
Five Ways to Deal With AWS DynamoDB GSI Throttling
A notorious performance bottleneck. But it can be solved.
Read on MediumUnderstanding DynamoDB Throttling
DynamoDB is a fully managed NoSQL database service designed to deliver fast and predictable performance to applications. It stores data across multiple partitions and provides single-digit millisecond response times.
However, handling increased load or demand may sometimes result in performance bottlenecks. In the context of DynamoDB, this bottleneck is known as throttling.
Throttling occurs when requests to DynamoDB exceed the provisioned throughput capacity. When this happens, database performance may be affected, and the service returns HTTP 400 status codes with an error type of ProvisionedThroughputExceededException.
Global Secondary Indexes (GSIs) are a powerful feature allowing you to create additional access patterns for your data.They have their own read and write capacityprovisioned separately from the base table. DynamoDB offers two types of capacity modes: provisioned and on-demand. In this article, we'll consider on-demand capacity mode.
In this blog post, we will explore how throttling on a GSI affects the base table, the importance of proper partition key design, and strategies to handle and prevent throttling when dealing with DynamoDB tables with GSIs.
How Throttling on a GSI Affects the Base Table
GSIs have their own provisioned read and write capacity units, separate from the base table. While this separation allows you to optimize GSIs for their specific workloads, it also means that if a GSI is throttled, it can have an impact on the base table's read and write operations.
Tip: you can use Amazon CloudWatch Contributor Insights for DynamoDB to identify the most frequently throttled keys.
Insufficient read capacity on GSI
If a GSI experiences throttling due to insufficient read capacity, the base table is not directly affected.
This is because the base table and GSI maintain separate read capacity units. However, user experience or application performance may still suffer due to delayed or unsuccessful read operations on the GSI.
Insufficient write capacity on GSI
Throttling on a GSI write operation has a more significant impact on the base table.
If a GSI does not have adequate write capacity, both the base table and its GSIs cannot complete write operations successfully.
Consequently, it is crucial to monitor and manage GSI write capacity carefully to avoid negative performance implications on the base table.
Example Scenario
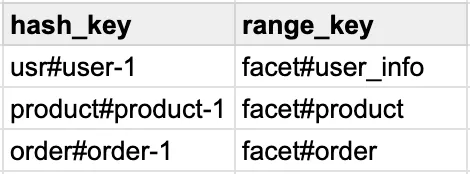
Imagine a situation where you have a Global Secondary Index (GSI) on your DynamoDB table, with a partition key GSI1HK having the value org#{orgId}.
You created a GSI to be able to query all the users' information by a single organization ID.
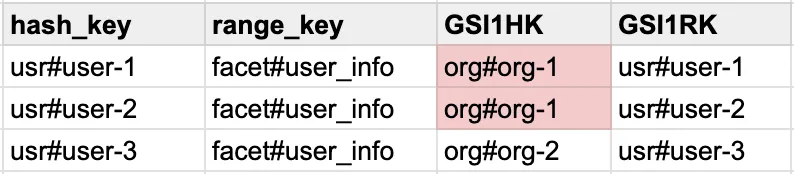
You did your schema design right, you read the best practice of partition key design and chose a high cardinality value for the hash_key which is user_id.
user_id is unique enough to prevent write throttles, right?
But your table will face throttling issues if you're consistently writing over 1MB/s of data for a single organization.
Under the hood of GSIs. Why does this problem exist?
This can be explained by the fact how DynamoDB implements GSIs. GSIs are essentially a virtual copy of your table and DynamoDB with a different partition key. DynamoDB just encapsulates the logic of replicating your items as you write them into a new shadow table.

So in reality, what happens, is DynamoDB is updating a "shadow" table in an eventually consistent fashion. And that "shadow" table now has a poorly optimized partition key, with low cardinality!
So all your writes to the base table with different user IDs are being properly distributed across partitions to prevent bottlenecks. However, in the GSI with partition key GSI1HK as org#{orgId}, the writes for a single organization might result in a hot partition, leading to throttling.
Possible Remedies
All those approaches assume you are ok to undergo minor modifications to your GSI key format but still be able to query all the data in a table by that GSI.
We are focusing on the write throttling problem, but most of the approaches are still applicable to mitigate read throttles.
A Table with Multiple Facets: Append facet to GSI
When architecting your DynamoDB schema, it's quite common to follow a single-table design pattern, where multiple types of data are stored in one table. This approach has some benefits, like reducing the number of tables to manage and allowing better capacity utilization. However, it can also lead to challenges when it comes to the impact of hot partitions and throttling on your GSIs.
Consider a use case in which you store data about products, users, and orders in a single table. Instead of having separate tables for each data type, they all coexist in one table, distinguished by different facet types.
In such cases, splitting tables by facet can help you distribute the load and reduce the impact of throttling. To achieve this, append the facet type to the GSI hash key, allowing the partition key to balance the read and write operations across multiple partitions.
For example, if your original GSI partition key is GSI1HK=org#{orgId}, you can modify it to include the facet, like GSI1HK=org#{orgId}#product, GSI1HK=org#{orgId}#user, and GSI1HK=org#{orgId}#order.

This division of partition keys distributes data more evenly across partitions, reducing the chance of hot spots and improving scalability. This will not only mitigate throttling issues but also make your table more maintainable and your capacity usage more efficient.
Yes, it will make it harder to query all the data belonging to a single organization. With the old design, you could query a table with a single request by GSI1HK=org#org-1, but now you need to issue multiple requests for different facets. So consider your requirements, to see can you trade the latency of querying all data by an organization for reducing the chance of write throttles.
| Pros | Cons |
|---|---|
| Mitigates throttling issues as long as your table has multiple facets. | Doesn't apply when you have a single facet; one hot facet could still lead to throttles. |
A Table with Multiple Facets: Use Multiple Tables
Consider the same example as in the previous section. Another approach is to avoid single-table design pattern and store different facets in separate tables.
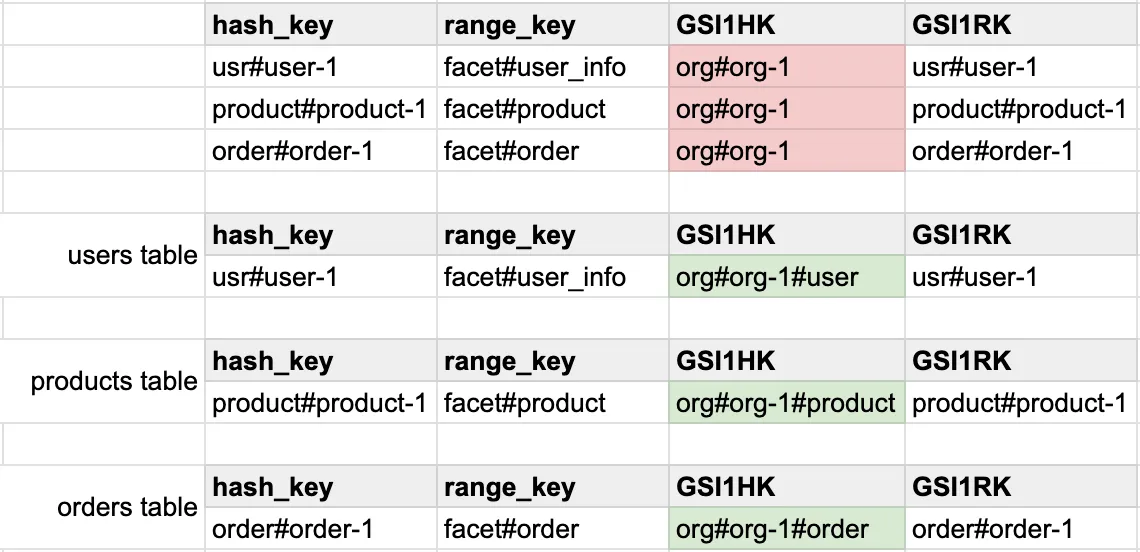
This is a very similar approach to the previous one with the same drawbacks: slower query latency when you need to fetch all data by one organization, with the added complexity of having to manage multiple tables.
| Pros | Cons |
|---|---|
| Works when you have multiple facets in one table. | Defeats the purpose of a single-table design. |
Adding suffixes to partition keys for shard distribution
Another approach to alleviate throttling and distribute the load on your DynamoDB table is by adding suffixes to your partition keys to create shards.
Shards are partitions that distribute your data across multiple distinct partitions (or nodes) based on a portion of the partition key. This helps DynamoDB by having higher cardinality values in your keys. The risk of hot partitions and throttling is significantly reduced.
Depending on the volume of data belonging to a single organization, you can append a deterministic shard number suffix to your GSI key. For example, a number of 1 to 20.

This approach makes GSI key 20 times more unique, and reduces the chance of write throttles by 20 times!
However, it increases query latency by 20 times as well.
| Pros | Cons |
|---|---|
| Agnostic to a number of facets in a table. | More complex and slower queries by GSIs. |
| Easy to scale by increasing the number of shards. |
Implementing SQS/Kinesis for write spike management and eventual consistency
In scenarios where your DynamoDB table experiences sudden spikes in write activity, a common solution to address this is to use an intermediate scalable buffer like Amazon SQS or Kinesis. By employing either of these services, you can distribute high-traffic workloads and ensure eventual consistency for data writes to your DynamoDB table.
This approach works for cases, where you write to your tables directly as a result of the user's API request, and don't care much about data being available for reading in the table immediately.
The idea is to control the speed of ingesting data and writing to a table by tuning the SQS/Kinesis parameters, such as batch size, polling interval, and Lambda's reserved concurrency.
This is called a Queue-Based Load Leveling pattern.
| Pros | Cons |
|---|---|
| Agnostic to a number of facets. | Applicable if you don't have strong write consistency requirements. |
| Scales indefinitely. | Additional infrastructure cost incurred. |
Employing the CQRS pattern
The Command Query Responsibility Segregation (CQRS) pattern is a powerful approach to address specific performance issues related to high write throughput and complex query scenarios in DynamoDB. By separating your application's responsibilities into separate command and query models, you can optimize these components to focus on their specific roles, while ensuring eventual consistency between the two.
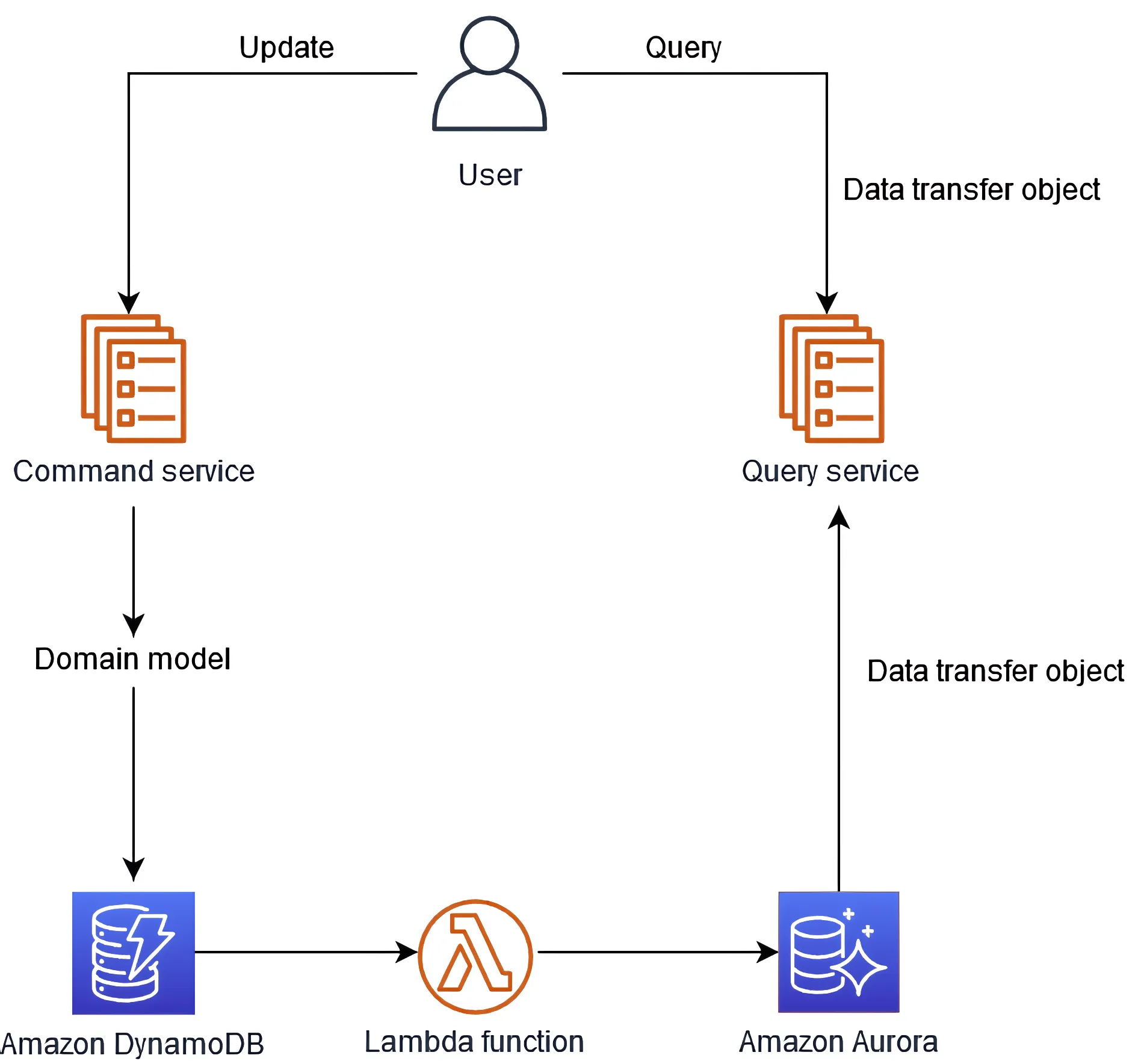
In this case, you would write data directly to DynamoDB without employing GSIs and store the data required for complex queries in a secondary data store, such as Amazon Aurora.
Then, you query data by organization ID from a secondary data store.
| Pros | Cons |
|---|---|
| Agnostic to facets. | Harder to implement. |
| Scales as long as secondary data store scales. | Requires having a different database. |
Conclusion
In conclusion, throttling issues with DynamoDB Global Secondary Indexes can impact both the base table and the overall performance of your application. Proper partition key design and consideration of various approaches to handle throttling can aid in mitigating high-traffic workloads and ensuring scalable system performance.
Some of the possible remedies include:
- Appending facets to the GSI.
- Using multiple tables.
- Distributing data via shard suffixes.
- SQS/Kinesis for load leveling.
- CQRS pattern.
Assessing each strategy's pros and cons according to your specific use case and requirements will help you maintain the balance between performance, scalability, and data consistency for the best overall experience.