
How to Scan a 23 GB DynamoDB Table in One Minute
For the cases when you screw up schema design.
Read on MediumWhile running DynamoDB workloads in production with over 500 GB of data for a couple of years, I accumulated a couple of lessons learned that I'll be sharing. One of them I wrote previously about: How to Speed-up Long DynamoDB Queries by 2x.
AWS DynamoDB is a great database. It's blazing fast, reliable, and infinitely scalable. However, the query language is quite limited. The flexibility of your queries heavily depends on the Hash Key design, which you can read about here.
Problem
While you can go a long way with CRUD operations over a small subset of items (<1,000), sometimes you find yourself in a situation where you need to query a large table by an attribute that is not a part of your hash key.
Imagine a table consisting of the user's notifications, where the hash key is the user's ID.
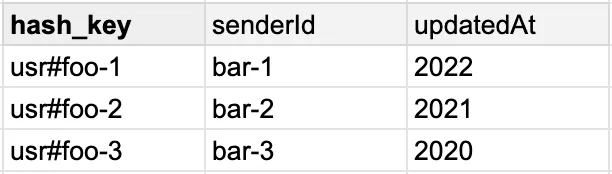
There are basically two primary recommended APIs to fetch data from DynamoDB:GetItem and Query. With GetItem you're limited to fetching 1 single record by its key, and with Query, you can fetch multiple records that share the same key.
But what if you want to query an item based on an attribute, that is not in the key? For example, by senderId as in our example?
AWS DynamoDB provides an API for that: Scan. However, it comes with a lot of caveats:
- Scanning is slow. Extremely slow. It's basically a brute-force mechanism to scan your entire table, each record one by one.
- Scanning is expensive. With DynamoDB, you pay for the Read Request Units you consume. And by scanning the entire table, you'll pay $1.25 for a 10 GB table.
- Scanning is cumbersome. Scan API is paginated. Each Scan request returns up to 1 MB of data. So to scan a 10 GB table, you'll need to paginate sequentially to make 10,000 requests.
So if Scan API is so bad, why would you ever want to use it? For sure, you must not use it in production code, but there are other use cases as:
- Migrating data out of the DynamoDB table to another table or another datastore.
- Finding a small subset of data from the entire table, for debugging purposes.
Actually, there are plenty of AWS services that use DynamoDB Scan API under the hood. For example DynamoDB to S3 Export or AWS Athena Federated Query.
Let's say you evaluated all the cons and decided to use Scan nevertheless. We cannot make it cheaper. But we can make it faster and easierto use! Let's see how.
Solution: Speed
To address the first problem of speed, we can use a Parallel Scan. I am quoting the AWS Documentation here:
By default, the
Scanoperation processes data sequentially. Amazon DynamoDB returns data to the application in 1 MB increments, and an application performs additionalScanoperations to retrieve the next 1 MB of data.Scan operation can logically divide a table into multiple segments, with multiple application workers scanning the segments in parallel.
Here is an excellent illustration from AWS Docs:
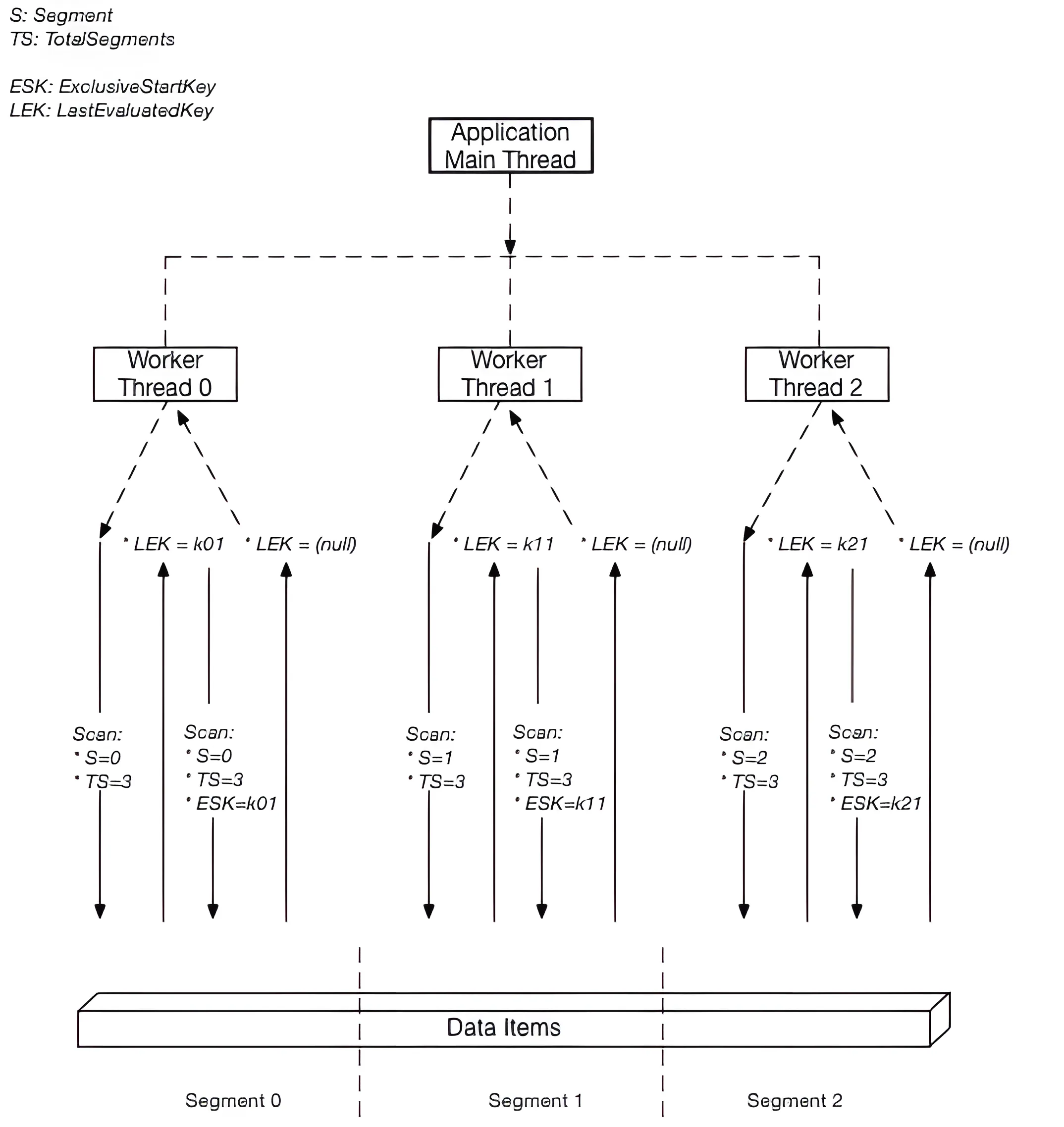
The idea is to issue Scan API requests in parallel, by providing the Segment and TotalSegments parameters:
- Worker #1: Segment: 0, TotalSegments: 10
- Worker #2: Segment: 1, TotalSegments: 10
- Worker #3: Segment: 2, TotalSegments: 10
- … and so on
By doing so, your table will be virtually divided into many segments, and then you paginate through the results of each segment, just like you did with the regular Scan API call.
And a great thing is, the maximum number of segments you can request is 1,000,000! So if your table is 10 GB, and you split it into 1 M segments, each worker would need to scan only 10 MB of data, which equals 10 requests only.
Each worker could be either a dedicated thread in your process, or it could be even a different server, or even better, a Lambda function.
So we have found a way to overcome the speed problem. By using parallel scans, we can greatly speed up scanning. Now let's take a look at the ease of use aspect of a problem.
Solution: Convenience
Keeping track of all the segments and paginating through results is not a fun coding problem to solve when you need to get something done. Fortunately, I've created a Node.js library to help solve this problem.
Github Repo: dynamodb-parallel-scan
This library encapsulates the logic behind many things you need to remember when you implement parallel scanning:
- Keeping track of scan segments and controlling the concurrency of requests.
- Getting a stream of items as they appear during scanning vs fetching all of them at once.
- Backpressure mechanism to avoid hitting process memory limits when fetching large volumes of data. It will pause scanning requests until you process the previous chunk of data.
Here is a sample code of using a library to scan a table with 1,000 parallel requests:
This approach is great when you know that the data you're going to fetch will fit into your memory, and you are ok with getting the data once a full table scan finishes.
Another way of fetching the data in a streaming manner is useful when the volume is too high to keep in memory, so you want to consume a chunk of the scanned items as soon as they accumulate.
You can control the concurrency, chunk size, and the high watermark, which controls the backpressure mechanism to avoid fitting too much data into memory. The library will pause scanning until you're able to iterate to the next chunk of data.
Great, let's look at the benchmarks now.
Performance Benchmarks
Here is the code snippet I used to run the benchmark. The benchmark will run on a single machine in a single process.
I am going to run the script with the DEBUG=ddb-parallel-scan environment variable in order to see the debug output of the library as it performs a scan.
I have a DynamoDB table that is 23 GB in size and has 36,000,000 records. Each record is 600 bytes on average.
The first time, I run the script with the concurrency: 1 , and the next time I run it with concurrency: 250.
As the code runs, here is a glimpse of the debug output:
You can see:
- which segment is currently being paginated (145–224).
- how much time it takes (~200ms on average).
- how many items were fetched that meet the filtering criteria (920 so far).
- and the progress of the scanned items (34 out of 36 million items were scanned).
Let's compare the results!
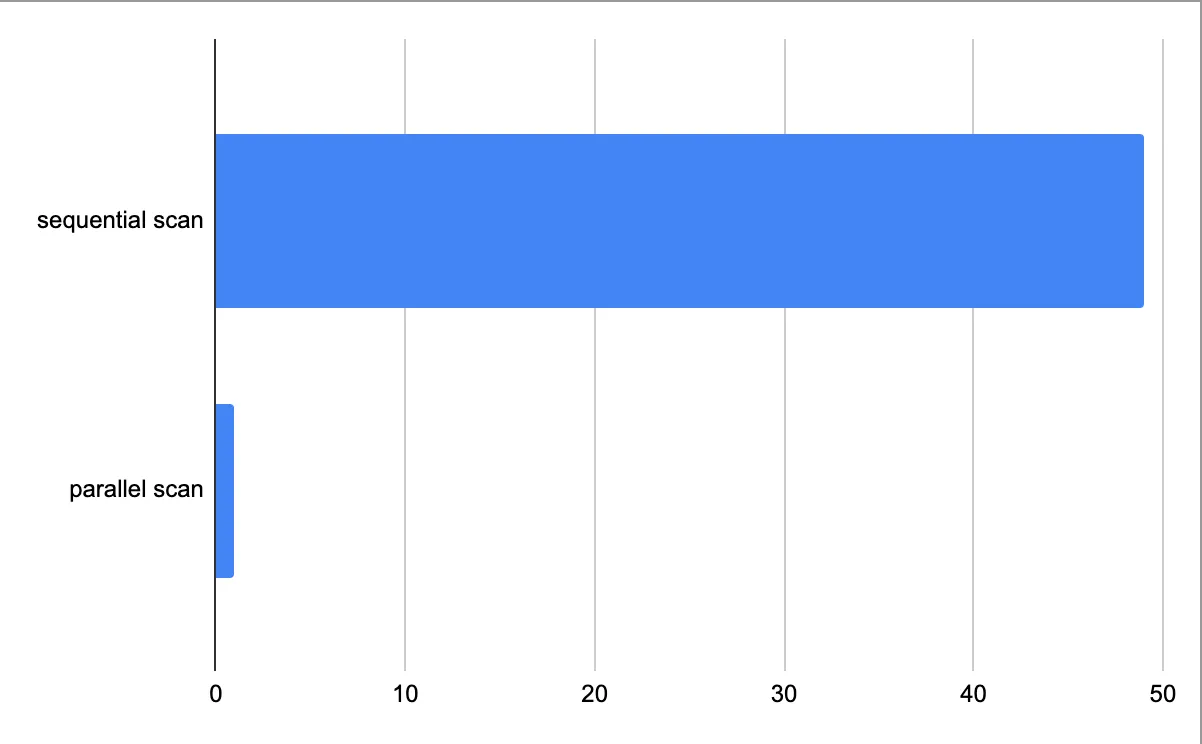
So in my example, by running the script on the t4g.small EC2 instance, I was able to scan a 23 GB table in just 1 minute! While the sequential scan took 49 minutes. 50x faster! Not bad!
The only time you won't see a performance improvement, is when your hash key distribution is not uniform enough. If you have a table where 100% of items have the same hash key — DynamoDB won't be able to split your table into segments. Your code will end up scanning one segment at a time.
So as a rule of thumb, don't attempt to set a concurrency higher than a number of unique hash key values in a table. The illustration below shows a good (left) and a bad (right) hash key design.

Uniformly unique hash keys on the left, and unbalanced hash keys on the right. Parallel scanning will work better for the table on the left, and won't have any positive effect on the second table.
Cost
While running the scan, our table peaked at ~43,600 Read Capacity Units consumed.
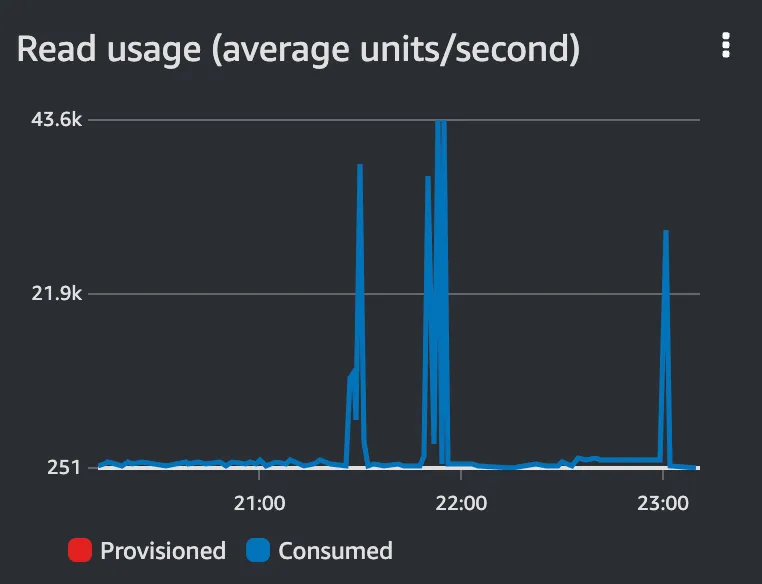
A single scan over such a table will cost us $2.88. Here is a link to the AWS Cost Calculator saved report.
Note, that my table has On-Demand capacity mode enabled. This means AWS will scale up the read capacity of the table as needed, temporarily just for the one-time scan operation. If you are on provisioned capacity mode, you might want to fine-tune the concurrency parameter to avoid throttling.
Summary
DynamoDB Scan API provides a way to issue concurrent requests to scan a table concurrently. Using 100–200 segments in a single process will give you at least 50x improvement in the scanning speed.
If you want to go beyond that, make sure your machine has enough network bandwidth to handle so many concurrent requests. If not — consider splitting the scan operation across multiple machines.
For convenience, you can use the dynamodb-parallel-scan node.js library, or read the implementation for inspiration for implementing it in other programming languages.
If you liked this article, consider following me to read more about lessons learned (and horror stories) around DynamoDB, AWS, and Serverless.