
How to Speed-up Long DynamoDB Queries by 2x
TL;DR; Implement parallel pagination from both ends instead of a sequential one.
Read on MediumNote: "Long" queries are the ones that scan over 2 MB of data. The trick described in this article only applies to those.
TL;DR; Implement parallel pagination from both ends instead of a sequential one.
Situation
Imagine you're in a situation when you have thousands of items under the same partition key, and you need to find only a couple of items using FilterExpression.
For the sake of the example, let's use the following table schema and try to find items where number > 0.5.
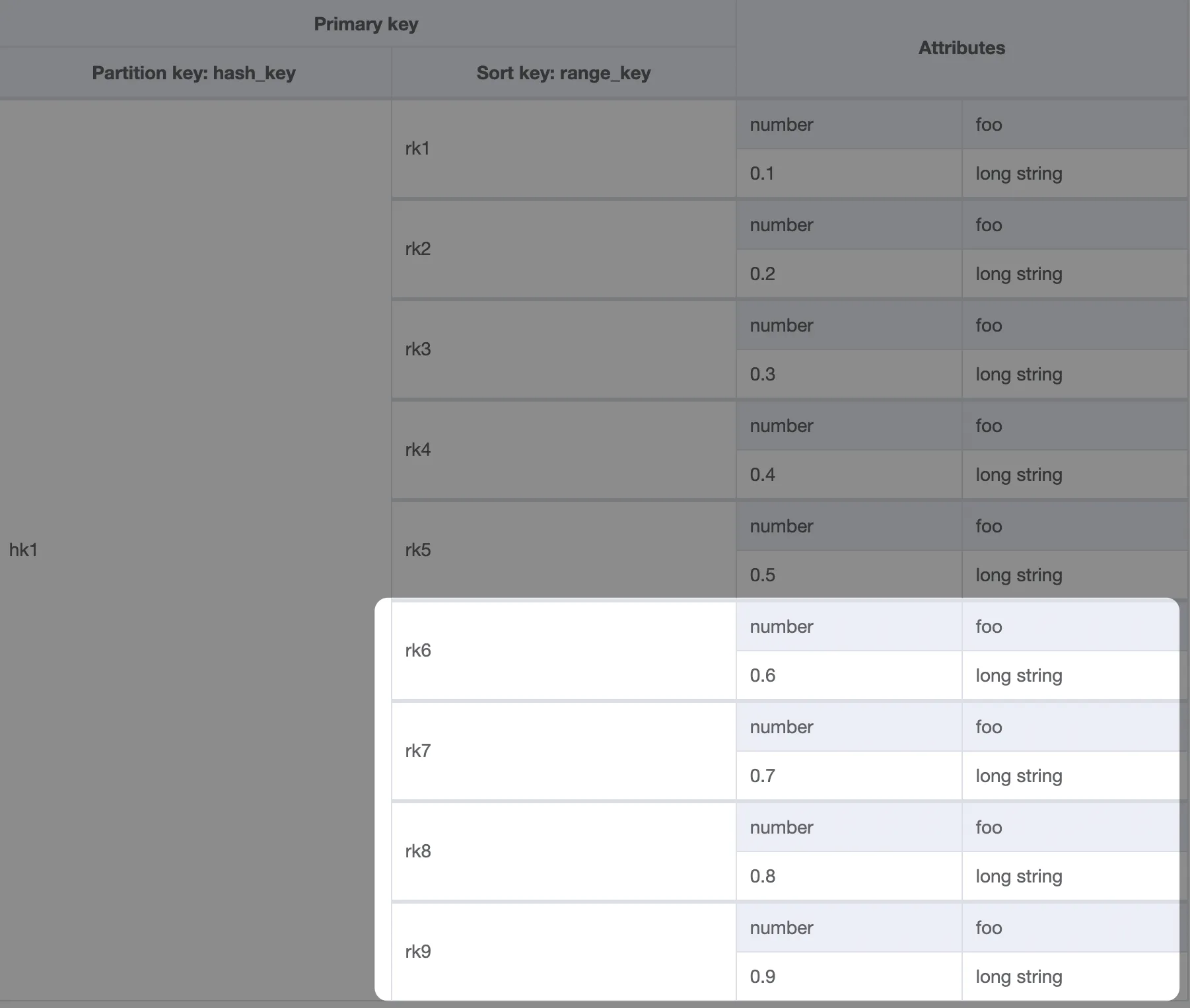
Schema created with NoSQL Workbench
Here is the query you'll end up with:
Since we know the partition key, those items could be queried with Query rather than Scan operation.
Problem
You might think that DynamoDB Query operation is fast, but it has its own limits. As per documentation:
A single
Queryoperation will read up to a maximum of 1 MB of data and then apply any filtering to the results usingFilterExpression. IfLastEvaluatedKeyis present in the response, you will need to paginate the result set.
See, if you have thousands of items under the same partition key that exceed 1 MB, DDB will query up to 1 MB of data in 1 request. Then, it's up to you to implement pagination logic.
With the sample table I created, it took ~450ms for each query operation. When you have 20 MB of data to scan, it can take ~10s to get the results you want if you implement sequential pagination.
I'll leave the speculation that having such a data structure in DDB is wrong, and discuss only the solution to the problem at hand.
Here is a diagram of the sequential iteration.

In the scenario when each query takes 5s, 4 queries will take 20s to complete.
Side Note: Think Twice About This Approach
Using DynamoDB to query over thousands of items is not the best practice. But sometimes you really need this.
Usually, I'd recommend creating Global Secondary Indicesfor such scenarios to avoid performance bottlenecks. But they come with some downsides. Sometimes you're not in control of a table to create an index, indices come with the added cost, indices can't guarantee strong read consistency, or you reached the quota of a maximum number of indices.
So first, try to think about how to avoid such a situation altogether by changing the sort key design or using indices. If all you need is just make a query 2x faster w/o spending time to re-architect, then proceed reading.
Solution
I've developed an NPM package that implements concurrent pagination from both ends: dynamodb-query-optimized. I'll explain how it works.
DDB Query operation allows you specifyingScanIndexForward: true/false parameter.
If
ScanIndexForwardistrue, DynamoDB returns the results in the order in which they are stored (by sort key value). This is the default behavior. IfScanIndexForwardisfalse, DynamoDB reads the results in reverse order by sort key value, and then returns the results to the client.
This parameter allows us to make 2 queries in parallel from both ends. The first query paginates through items from the beginning, and the second query paginates through items from the end. Pagination stops when each query reaches the middle.
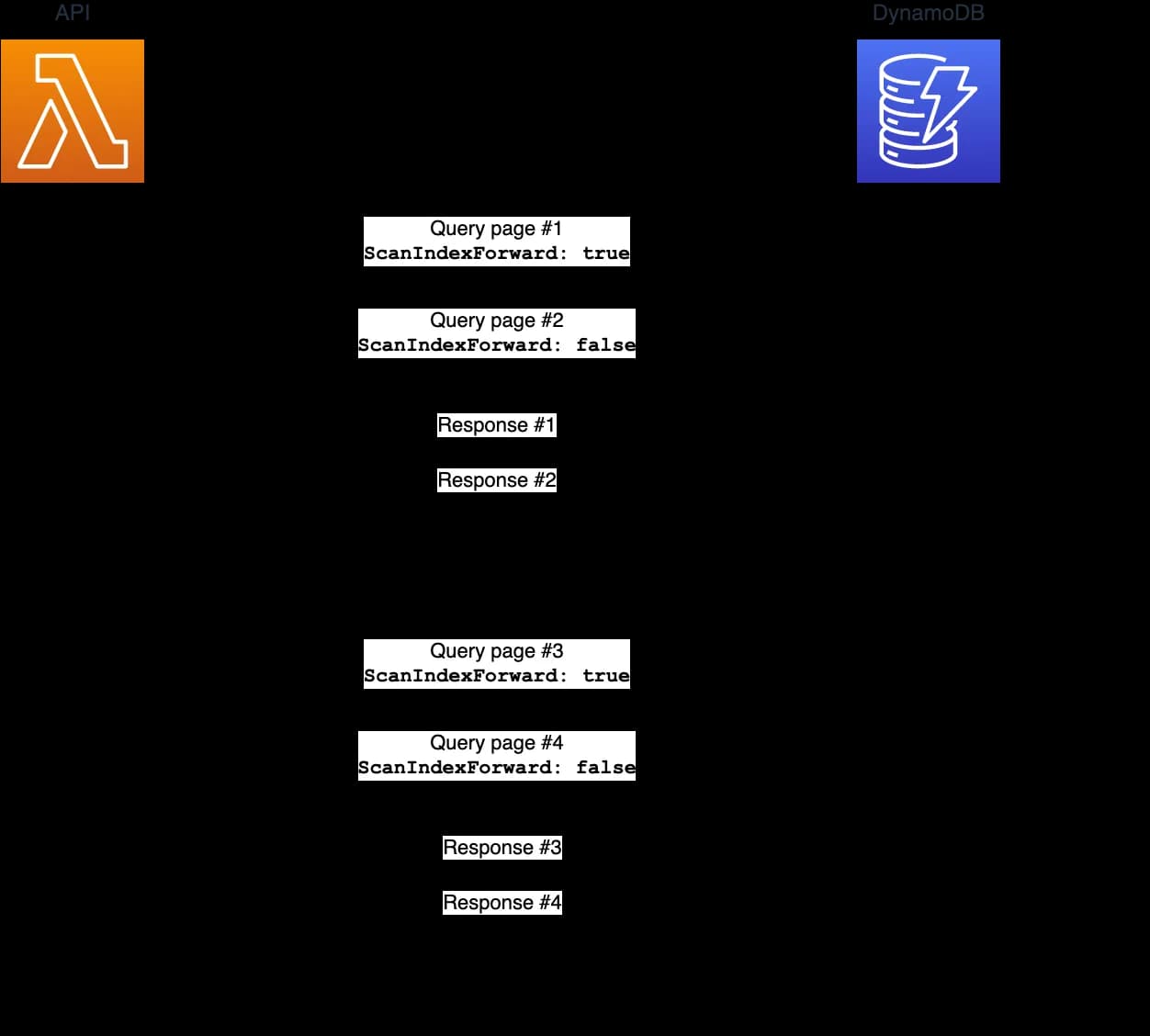
This simple trick shaves off a total query time by 2x!
Benchmark
I created a sample table and populated it with ~21 MB of data and wrote a query to find all items under the partition key hk6 and number > 0.5.
Here are the results of the benchmark script:
The optimized query is almost 2x faster when run locally. It would be even faster if executed in the AWS environment, be it a Lambda of an ECS service.
Note: this method works slower when you query <2 MB of data due to added network latency for making additional requests.
So you need to understand how many items are under your partition key before using this optimized query method.
Wrap Up
I got the inspiration for this solution while answering this Stack Overflow question.
Here is the NPM package dynamodb-query-optimized.
As a bonus, I included the queryRegular method in the library that conducts pagination sequentially for those cases when you have less than 2 MB of data to query.